Modalitynet Technical Specification v1.0
Introduction to the Three Datasets
| version | date |
|---|---|
| 0.51 | 20260123 |
| v1.0 | 20260511 |
Disclaimer
This document contains proprietary and confidential information of Noitom Robotics and is intended for authorized academic and/or technical review only. No part of this document may be reproduced, disclosed, distributed, or otherwise made available to any third party, in whole or in part, without the prior written consent of Noitom Robotics. Any unauthorized use of this document is strictly prohibited.
| Feature | HiPHI Motion with Object & Vision (HiPHI-MOV) | HiPHI Omni-Modality (HiPHI-OM) | In-The-Wild (ITW) |
|---|---|---|---|
| Primary Goal | Locomotion-Manipulation | Ground-truth Precision | Real-world Robustness |
| Environment | Transitionary / Complex | Controlled Lab | Unconstrained / Unstructured/Stochastic |
| Key Sensor | Synchronized RGB-D + MoCap | Optical + IMU Fusion | Portable/Sparse Arrays |
| Action Scale | Hierarchical (Micro to Macro) | Atomic & Meso-level | Ecological/Naturalistic |
| Ontology | Morphological Abstraction | Cross-Ontology Mapping | Cross-Ontology Annotation |
Overview
High Precision Human Interaction Motion With Object & Vision (HiPHI-MOV) Dataset: The HiPHI-MOV Dataset is a human-centric, high-fidelity multimodal corpus specifically engineered for the development of robust locomotion and whole-body loco-manipulation policies. It includes full-body motion capture, tracking of interacting objects, third-person RGB-D visual data. HiPHI-MOV provides a synchronized data stream that co-registers ground-truth, full-body kinematic trajectories—captured via high-frequency motion capture—with ego-centric and exo-centric visual observations. This structured hierarchy enables the modeling of complex robotic behaviors, ranging from low-level motor primitives (joint-space dynamics) to high-level environmental affordances (scene-contextual navigation).
High Precision Human Interaction Omni-Modality (HiPHI-OM) Dataset : The HiPHI-OM Dataset is a human-centric, high-fidelity, omni-modal repository acquired within a highly instrumented laboratory environment. It includes full-body and fine-grained hand motion capture, hand-level tactile sensing, precise tracking of interacting objects, egocentric RGB-D visual data, and third-person RGB-D visual data. By utilizing synchronized, high-precision sensor arrays, HiPHI-OM provides ground-truth level data for anthropocentric modeling with minimal aleatoric uncertainty. The dataset is designed to be ontology-agnostic, allowing for the decoupling of raw sensor data from specific semantic frameworks to maximize cross-domain generalization and longitudinal utility. Morphologically, the dataset supports a hierarchical structure, encompassing both micro-level kinematic primitives and meso-level sequential task planning.
In the Wild (ITW) Dataset : The In-the-Wild (ITW) Dataset constitutes a human-centric, life-scale, diverse, open-world, multimodal repository of stochastic real-world scenarios designed to advance humanoid robotics and embodied intelligence (EI). It includes sparse-body motion capture sensors and egocentric RGB-D visual data. Departing from traditional laboratory-constrained acquisition, ITW captures ecologically valid human behaviors and interaction dynamics within unconstrained environments. By integrating high-variance environmental noise and long-tail edge cases into the training distribution, ITW facilitates the generalization of laboratory-optimized algorithms toward industrial deployment. When integrated with the HiPHI-OM dataset, it provides a comprehensive cross-domain corpus spanning diverse operational scenarios and sensory modalities.
1. Technical Specification: HiPHI Motion with Vision (HiPHI-MOV) Dataset
-
Multimodal Sensor Fusion and State Estimation: The HiPHI-MOV dataset provides a high-dimensional data stream that integrates 6-DOF full-body kinematics, high-fidelity hand-joint trajectories (provisioned), and synchronized RGB-D environmental telemetry. This deep fusion of proprioceptive and exteroceptive data supports the development of integrated perception–action loops, enabling models to learn the spatial relationships between body pose and environmental affordances.
-
Multi-Scale Hierarchical Interpretability: Designed as a structured benchmark for embodied intelligence, the dataset spans three distinct semantic layers: atomic-level action ontologies (kinematic primitives), mesoscopic task planning (sequential logic), and macro-level scene distributions (environmental context). This hierarchy allows for scientific interpretability in model performance, isolating whether failures occur at the motor-control, tactical, or strategic level.
-
Sim-to-Real Alignment and Zero-Shot Transfer: The dataset is engineered to facilitate sim-to-real alignment, providing the high-precision ground truth necessary to bridge the gap between virtual simulations and physical deployment. By capturing a diverse range of locomotion-manipulation tasks, HiPHI-MOV supports the evaluation of zero-shot transfer capabilities, allowing autonomous control algorithms to generalize to novel environments without additional fine-tuning.
-
Cross-Ontology Compatibility and Morphological Abstraction: Leveraging advanced motion retargeting frameworks, the HiPHI-MOV dataset decouples captured human motion from specific hardware constraints. This ensures cross-ontology compatibility, where high-fidelity motion data can be seamlessly mapped onto humanoid platforms with disparate degrees of freedom (DoF) and varied mechanical configurations. This abstraction is vital for creating platform-independent foundation models for robotic locomotion.
File Structure
Dataset Folder
| File Name | Description | Motion without Object | Motion with Object |
|---|---|---|---|
| motion_actor.bvh | Human motion data | ✔ | ✔ |
| task_info.json | Task information for this collection | ✔ | ✔ |
| config.json | Relationship between motion bvh and object | ✔ | |
| prop_Object.csv | Object motion information | ✔ |
*Video data will be provided soon.
Object Model Folder (only available for motion data with object)
| File Name | Description |
|---|---|
| Object.obj | Object model (with orientation Y up) |
| Object.csv | Object weight(kg) info |
2. Technical Specification: HiPHI Omni-Modality (HiPHI-OM) Dataset
-
Human-Centered Hierarchical Modeling: The dataset captures anthropocentric behaviors across multiple granularities, from atomic-level meta-actions to medium- and long-range task sequences. By maintaining an ontology-agnostic underlying structure, HiPHI-OM facilitates high-level cross-ontology generalization, allowing the same raw behavioral data to be effectively mapped to diverse semantic frameworks and research objectives.
-
Sub-millimeter Spatiotemporal Synchronization: The system achieves high-precision pose capture through a robust human–computer interaction (HRI) pipeline. By fusing optical markers with inertial measurement units (IMUs), the infrastructure ensures stable and accurate tracking during high-speed, high-acceleration motions. This hybrid approach minimizes occlusion artifacts and latency, providing high-fidelity recordings of complex human kinematics.
-
Multimodal, High-Dimensional Signal Registration: HiPHI-OM serves as a "ground-truth-level" repository, providing synchronized signals across visual, tactile, and spatial domains. While current releases focus on high-precision target positioning and tactile feedback, the architecture is designed for "full-modal" expansion, with integrated force, audio, and thermal telemetry scheduled for subsequent release cycles within the controlled environment.
-
Cross-Ontology Compatibility and Morphological Mapping: A core strength of the dataset is its hardware-agnostic nature, achieved through advanced motion retargeting technology. This allows for the seamless translation of human motion data to humanoid robots with heterogeneous degrees of freedom (DoF) and varying physical proportions. By decoupling the data from specific robotic platforms, HiPHI-OM ensures that the learned policies are robust across a wide spectrum of robotic morphologies.
File Structure
Data Structure
| File Name | Description |
|---|---|
| config.json | Metadata and description of the data in this collection |
| task_info.json | Task information for this collection |
| camera_params/ | Intrinsic and extrinsic parameters for all cameras |
| head_stereo_depth.csv | Index, timestamp, and PNG path for depth images from the head-mounted depth camera |
| head_stereo_depth/ | Depth maps from the head-mounted depth camera |
| head_stereo.csv | Per-frame timestamps for the video from the head-mounted depth camera |
| head_stereo.mp4 | Video from the head-mounted depth camera |
| head_wide.csv | Per-frame timestamps for the video from the head-mounted wide-angle camera |
| head_wide.mp4 | Video from the head-mounted wide-angle camera |
| fixed1_stereo_depth.csv | Index, timestamp, and PNG path for depth images from fixed camera 1 |
| fixed1_stereo_depth/ | Depth maps from fixed camera 1 |
| fixed1_stereo.csv | Per-frame timestamps for the video from fixed camera 1 |
| fixed1_stereo.mp4 | Video from fixed camera 1 |
| fixed1_wide.csv | Per-frame timestamps for the wide-angle video from fixed camera 1 |
| fixed1_wide.mp4 | Wide-angle video from fixed camera 1 |
| fixed2_stereo_depth.csv | Index, timestamp, and PNG path for depth images from fixed camera 2 |
| fixed2_stereo_depth/ | Depth maps from fixed camera 2 |
| fixed2_stereo.csv | Per-frame timestamps for the video from fixed camera 2 |
| fixed2_stereo.mp4 | Video from fixed camera 2 |
| fixed2_wide.csv | Per-frame timestamps for the wide-angle video from fixed camera 2 |
| fixed2_wide.mp4 | Wide-angle video from fixed camera 2 |
| hand_pressure_data.h5 | 6DOF data for the motion-capture subject’s skeleton |
| tracker_sixdof_data.h5 | Palm pressure data (all finger joints and palm regions: upper, mid, lower-mid, lower, base) |
| human_bones.h5 | 6DOF data for full-body trackers, hands, and props |
Obj Model Folder
| File Name | Description |
|---|---|
| Obj.fbx | A versatile file format developed by Autodesk for 3D animation, modeling, and design. Unlike STL, FBX files can contain not only the geometry of a 3D model, but also its textures, animation data, and more. |
| Obj.stl | A widely used file format for 3D printing. It represents the surface geometry of a 3D object using a series of connected triangles, making it a simple and efficient format for 3D printing. |
Data formats for various file types
Video data
Each scene contains a total of six video files from three channels: one head-mounted channel and two fixed camera channels. Each channel includes two videos: one binocular and one wide-angle. The video data is an mp4 file, accompanied by a csv file with the same name, which records the timestamp of each frame. For example, the head_stereo.csv file records the timestamp of each frame of the head_stereo.mp4 video.
Depth data
Each scene contains three channels of depth data: one head-mounted channel and two fixed camera channels. The depth data of each depth camera is uniformly placed in a folder, where each png file corresponds to one frame of depth data. The csv file with the same name records the timestamp of each frame of data. For example, the head_stereo_depth.csv file records the timestamp of each frame in the head_stereo_depth/ depth directory. The depth data of each png is 16-bit, and the following parsing script can be used to obtain one frame of data.
Parse code: read_png_16bit.py
Output result example:
H5 File
All structured data other than video data and depth data is stored in H5 format.
Each H5 file contains a dataset named data, which consists of multiple records, each corresponding to a single frame. Every record includes three fields: index (an np.int64 indicating the frame number, starting from 0 and increasing sequentially), timestamp (an np.float64 representing the time, where the integer part denotes seconds and the three decimal places indicate milliseconds), and elements, whose structure varies depending on the data type and is described in detail below.
Position and attitude data of the tracker
In each scene, there are trackers used to track the sub-millimeter level pose information (6dof) of some key objects, as shown in the following table:
| Name | Meaning |
|---|---|
| fixed1_cam | Fixed Camera 1 |
| fixed2_cam | Fixed Camera 2 |
| Head | Header |
| Spine | Back |
| Hips | Hip |
| RightUpLeg | Right thigh |
| RightFoot | Right Foot |
| LeftUpLeg | Left thigh |
| LeftFoot | Left Foot |
| RightHand | Back of right hand |
| RightHandThumb2 | Right thumb tip |
| RightHandThumb1 | Right thumb base |
| RightHandIndex2 | Right index finger tip |
| RightHandIndex1 | Right index finger root |
| RightHandMiddle2 | Right middle fingertip |
| RightHandMiddle1 | Root of the right middle finger |
| RightHandRing2 | Tip of the right ring finger |
| RightHandRing1 | Base of the right ring finger |
| RightHandPinky2 | Right little finger tip |
| RightHandPinky1 | Base of the right little finger |
| LeftHand | Back of left hand |
| LeftHandThumb2 | Left thumb tip |
| LeftHandThumb1 | Left thumb base |
| LeftHandIndex2 | Left index finger tip |
| LeftHandIndex1 | Left index finger root |
| LeftHandMiddle2 | Left middle finger tip |
| LeftHandMiddle1 | Root of the left middle finger |
| LeftHandRing2 | Left ring finger tip |
| LeftHandRing1 | Base of the left ring finger |
| LeftHandPinky2 | Left little finger tip |
| LeftHandPinky1 | Base of the left little finger |
| TBD | Other Props |
These datas are stored in the tracker_sixdof.h5 file, with sub-millimeter positional accuracy
Parse code: read_sixdof_data_h5_1.py
Output result example:
Human skeletal motion data
The human skeletal motion data (full body + fingers) calculated based on tracker data is included in the file: human_bones.h5
Hierarchy
In addition to the "data" dataset, the root directory of this file also contains a "skeleton" group, which defines information such as human body bone length and connection relationships, equivalent to the "HIERARCHY" in the BVH format. The root group is "Skeleton", and all bones are sub-groups under "Skeleton", with a parallel hierarchical structure. The information contained in each bone is included through attributes. An example is as follows:
Data
Elements contain all the bones of a human body in one frame
-
name (string, e.g. "hip"),
-
position (float32, shape=[3], e.g. x,y,z)
-
rotation ((float32, shape=[4], e.g. w,x,y,z)
Parse code: read_sixdof_data_h5_2.py
Output result example:
Palm Pressure Data
Palm pressure data is encapsulated in the hand_pressure.h5 file, with each palm containing 129 pressure points, and the value range of each point is 0 to 255.
Hand Pressure Point Map:
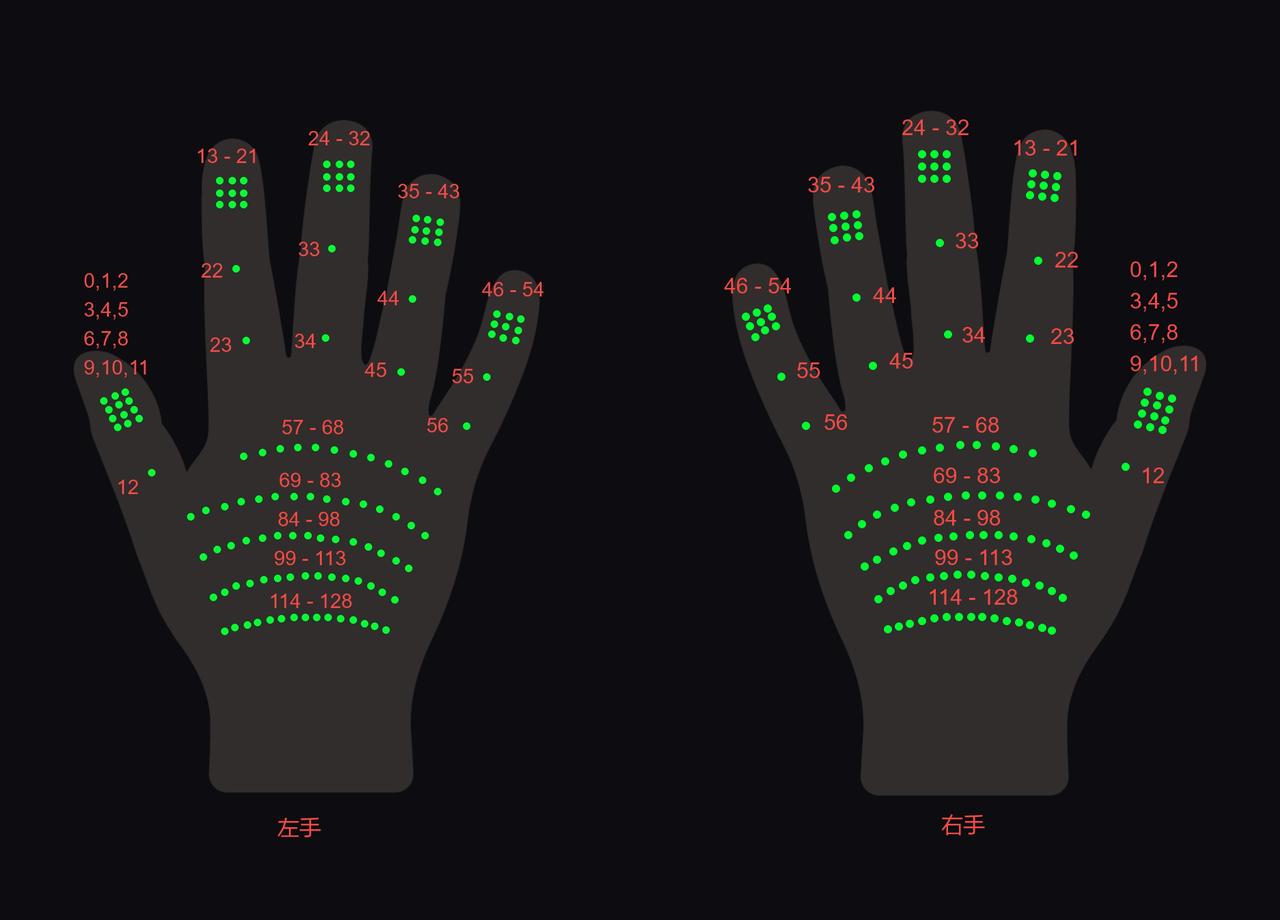
elements contain one frame of hand palm pressure data:
-
name (string, e.g. : "left" or "right")
-
value (uint8, shape=[129])
Parse code: read_hand_pressure_h5.py
Output result example:
Data Player
This software visualizes the various data points for each recorded entry.
After startup, open trackers_sixdof.h5 in the corresponding data directory. The program will automatically load other data files. The running effect is shown in the figure below:
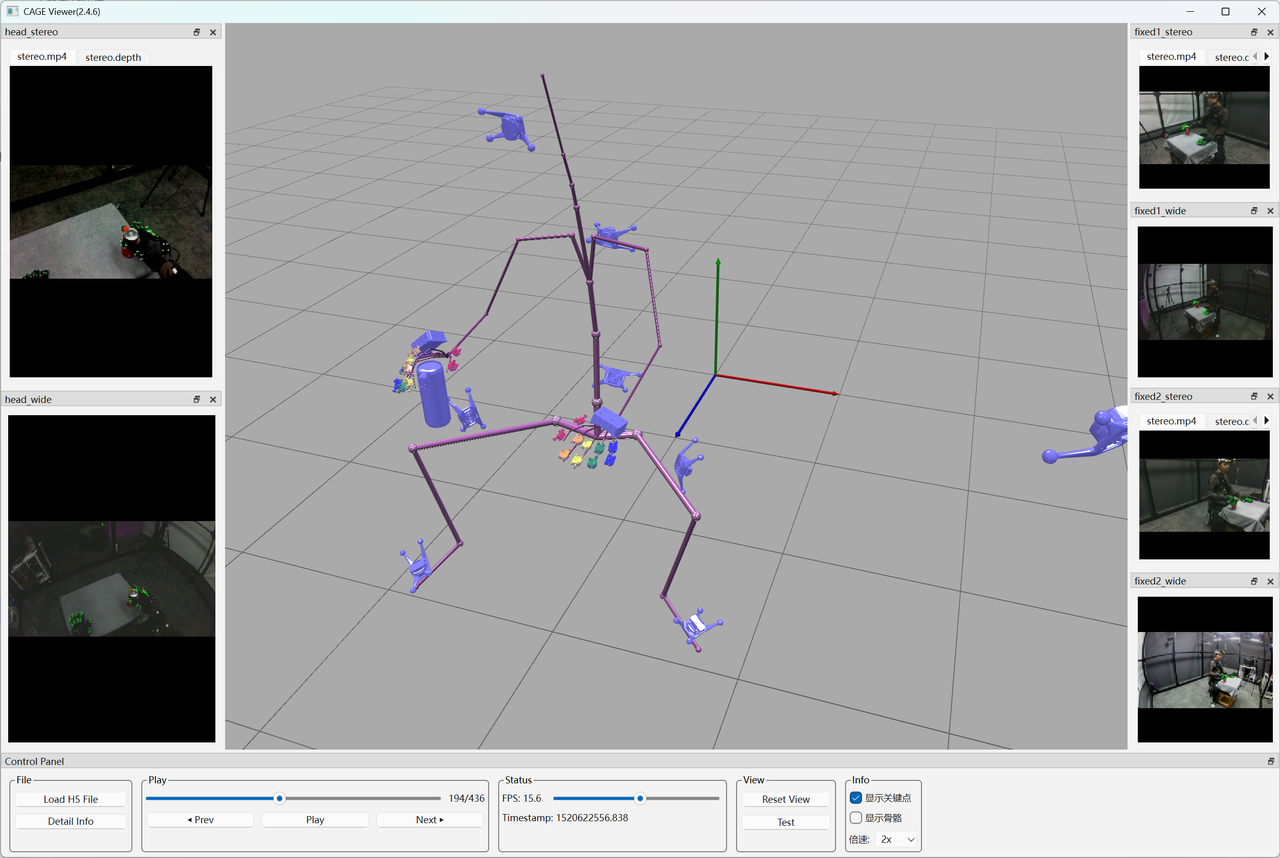
FAQ
Explain the system's coordinate system.
The tracker's 6DoF and human skeleton motion data share the same world coordinate system.
The origin of the world coordinate system is typically placed on the ground with the Y-axis pointing upward, as shown in the figure above. (i.e., the coordinate system of the optical environment)
The tracker's 6DoF data (trackers_sixdof.h5) represents the coordinate pose of its own model within the world coordinate system, with length units in meters.
The root node Hips in the human skeleton motion data (human_bones.h5) provides 6DoF data in the world coordinate system. Subsequent child bone data represent coordinate poses relative to their parent nodes, with length units in centimeters.
What are the different forms of trackers, and what do their coordinate systems look like?
A tracker is a combination of an optical rigid body and an IMU inertial sensor. Each tracker has its own name, as detailed in the "Tracker List". Currently, there are six distinct configurations. The model files, coordinate systems, and optical point topologies for each tracker configuration are defined as follows:
| Type Name | Model file | Diagram |
|---|---|---|
| PWR_M_PN3 | PWR_M_PN3_V2.stl | 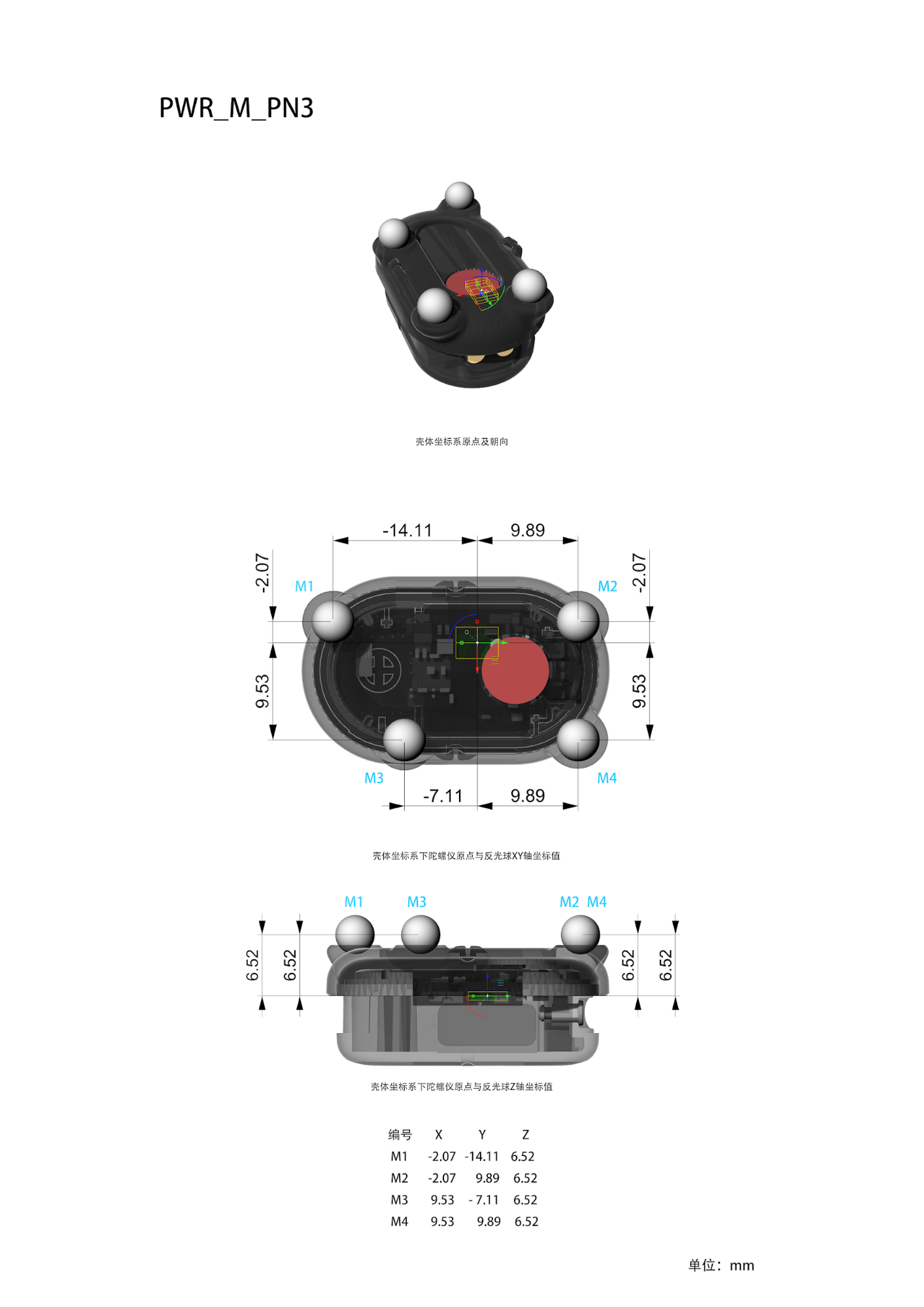 |
| PWR_K_PNS | PWR_K_PNS.stl |  |
| PWR_K_Link_V2 | PWR_K_Link_V2.stl | 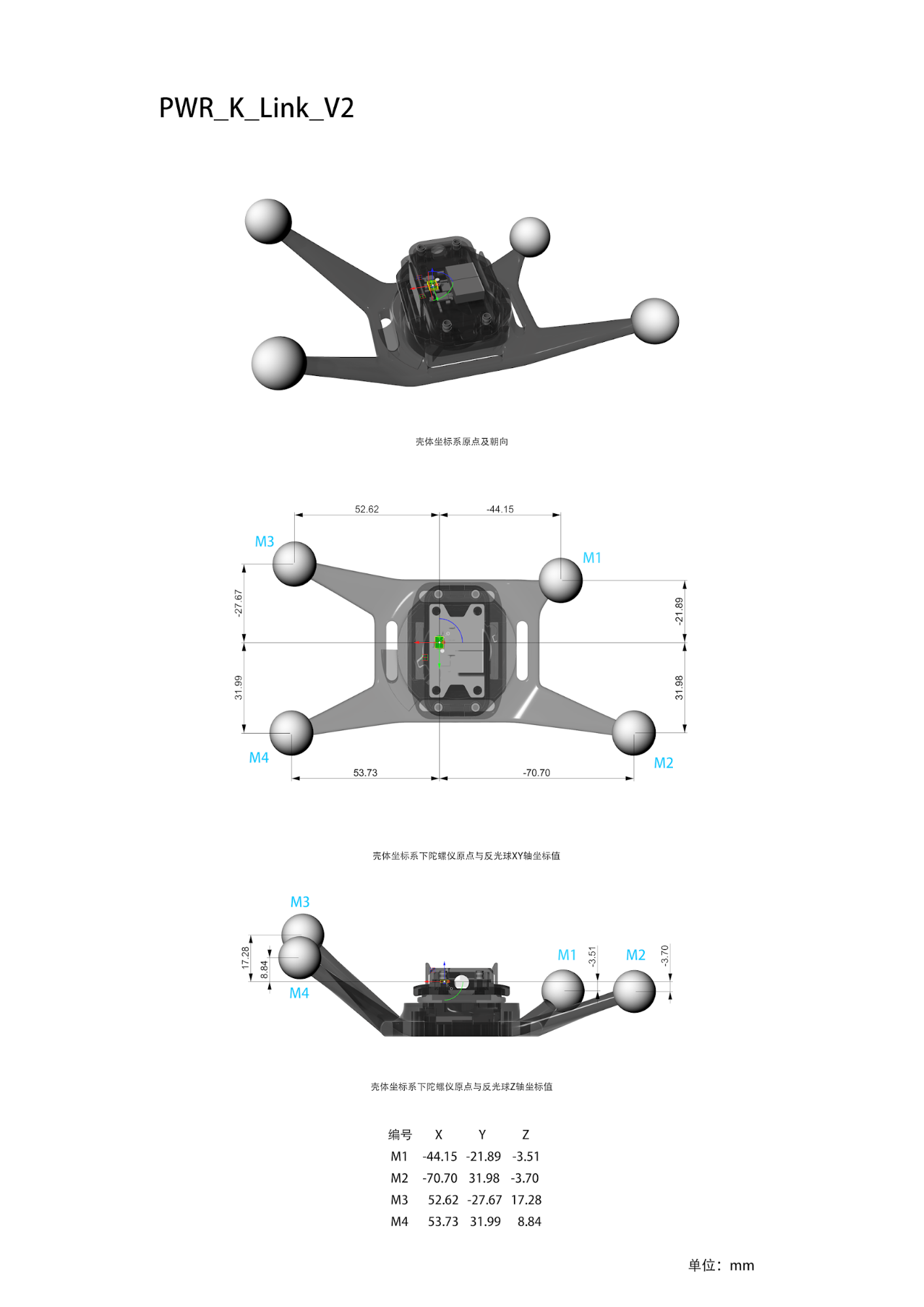 |
| PWR_H_LinkHand | PWR_H_LinkHand.stl | 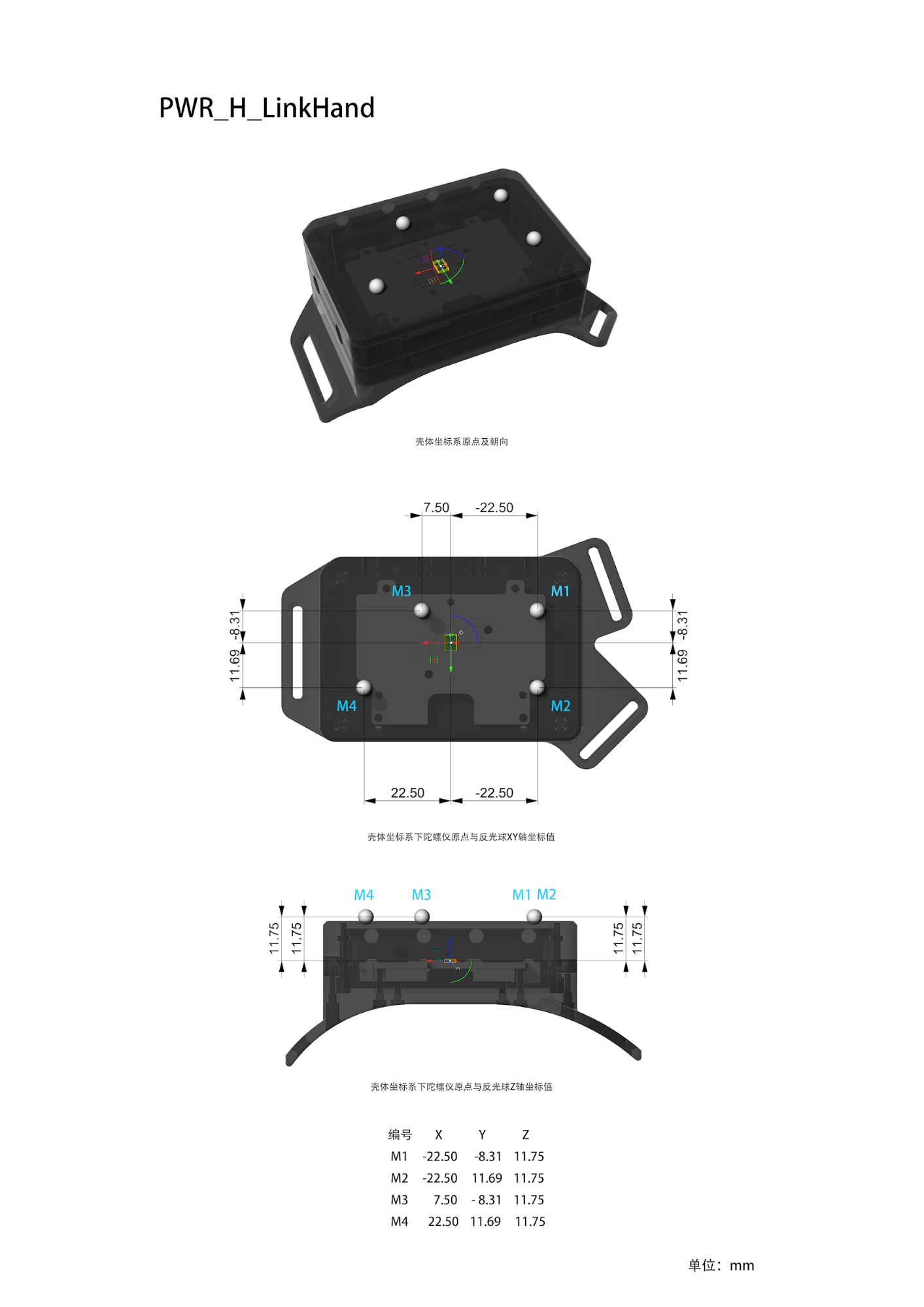 |
| PWR_M_FingerA | PWR_M_FingerA.stl | 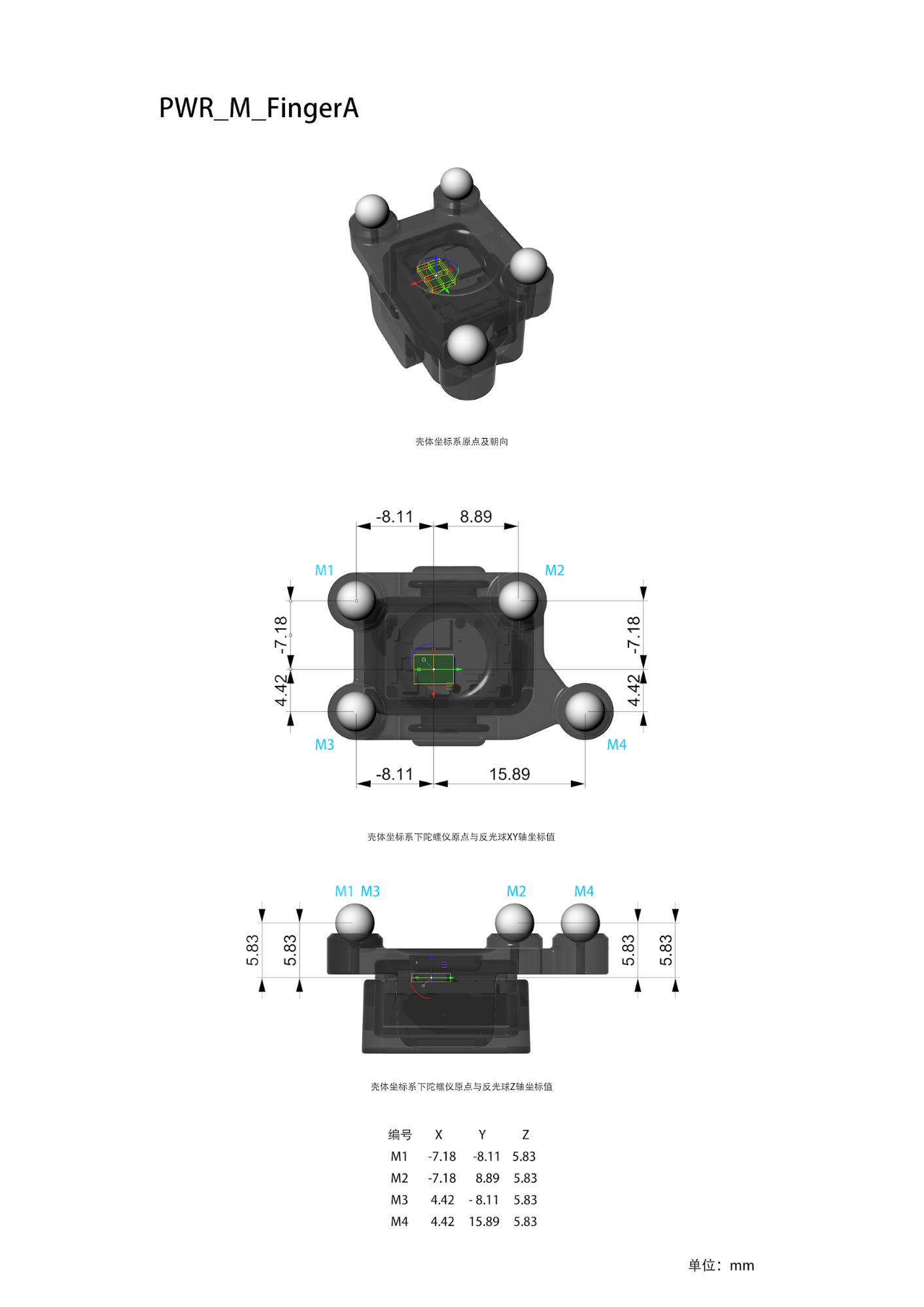 |
| PWR_M_FingerB | PWR_M_FingerB.stl | 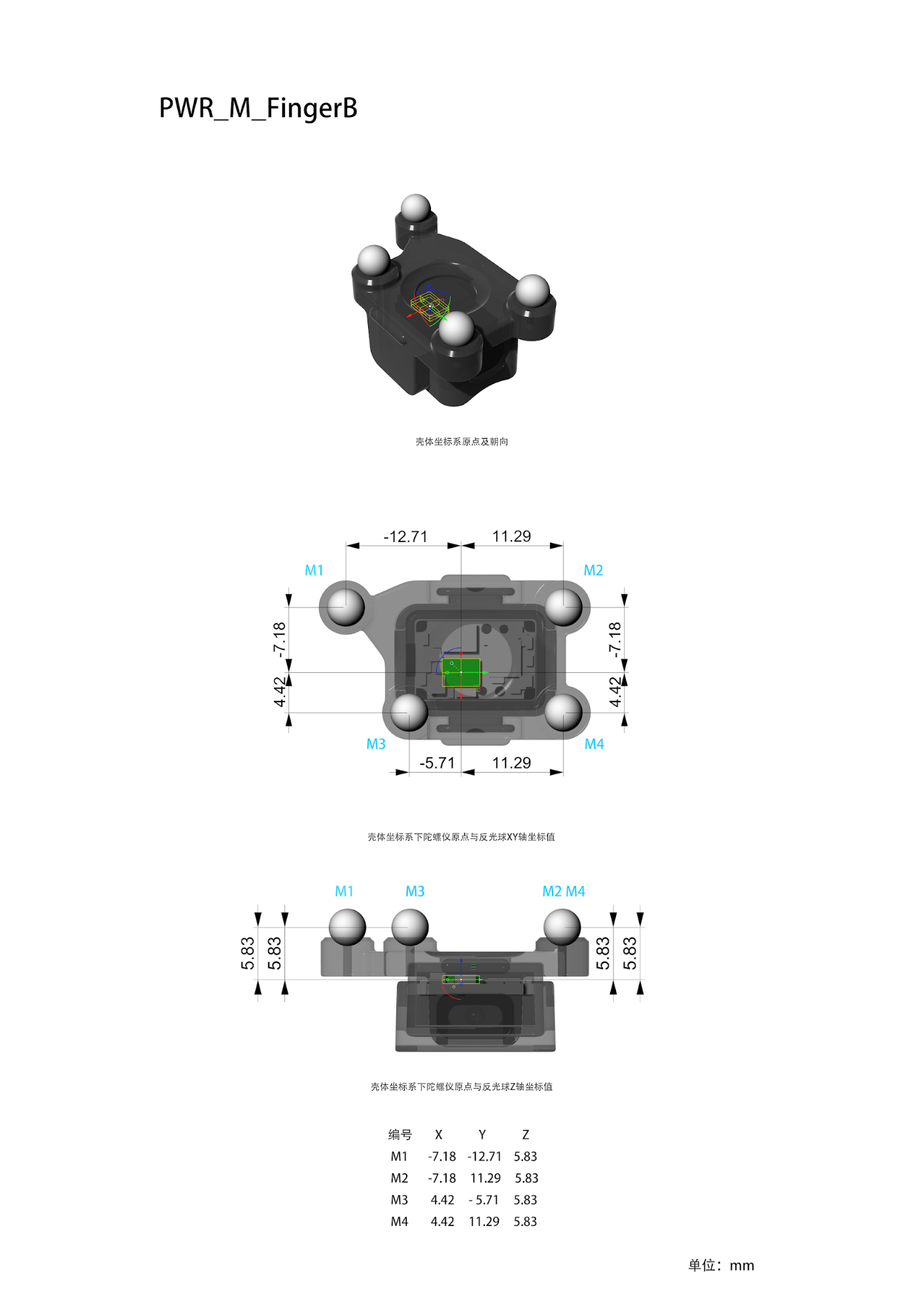 |
Where are these trackers used?
These trackers fall into two main categories: wireless trackers and wired trackers.
-
Wireless trackers are used for tracking props.
-
Wired trackers are used for tracking body parts.
Wireless trackers
-
PWR_M_PN3: A small wireless tracker attached to smaller props for tracking purposes.
-
PWR_K_PNS: A wireless large tracker designed for attaching to larger props such as tables, boxes, and dual fixed-position cameras.
Props equipped with wireless trackers have their model files aligned so that their origin point and orientation perfectly match those of the tracker. This ensures that after importing the prop model file, no coordinate conversion is required—the prop can be directly driven by the tracker's 6DoF data.
Prop Model File
The following table shows the model file for the cola can in the sample data.
| Tool Name | Model file | Diagram |
|---|---|---|
| cola_modern_330 | cola_modern_330_chip.stl | 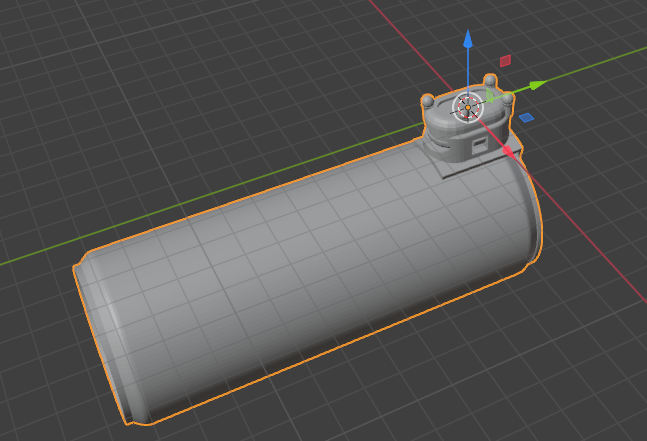 |
Wired trackers
-
PWR_H_LinkHand: Wired tracker mounted on the back of both hands
-
PWR_M_FingerA and PWR_M_FingerB: Both are wired trackers mounted on fingers, with one at the fingertip and one at the finger base for each finger.
Hand tracker diagram:

Tracker name and model correspondence
The correspondence between trackers and models is as follows: each recording session includes 6DoF data from at least 31 trackers, and this correspondence remains consistent across all recordings. (Additional trackers for props may be included based on the scene.)
| Name | Meaning |
|---|---|
| RightHandPinky2 | Right little finger tip |
| RightHandPinky1 | Base of the right little finger |
| LeftHand | Back of left hand |
| LeftHandThumb2 | Left thumb tip |
| LeftHandThumb1 | Left thumb base |
| LeftHandIndex2 | Left index finger tip |
| LeftHandIndex1 | Left index finger root |
| LeftHandMiddle2 | Left middle finger tip |
| LeftHandMiddle1 | Root of the left middle finger |
| LeftHandRing2 | Left ring finger tip |
| LeftHandRing1 | Base of the left ring finger |
| LeftHandPinky2 | Left little finger tip |
| LeftHandPinky1 | Base of the left little finger |
| TBD | Other Props |
How is the camera tracked, and how are external reference information and coordinate information defined?
The setup includes three camera channels totaling six cameras: one head-mounted camera and two fixed-position cameras. Each channel comprises one RealSense D435 camera and one USB wide-angle camera, connected using identical structural components as shown below.
| Camera Connection Diagram | 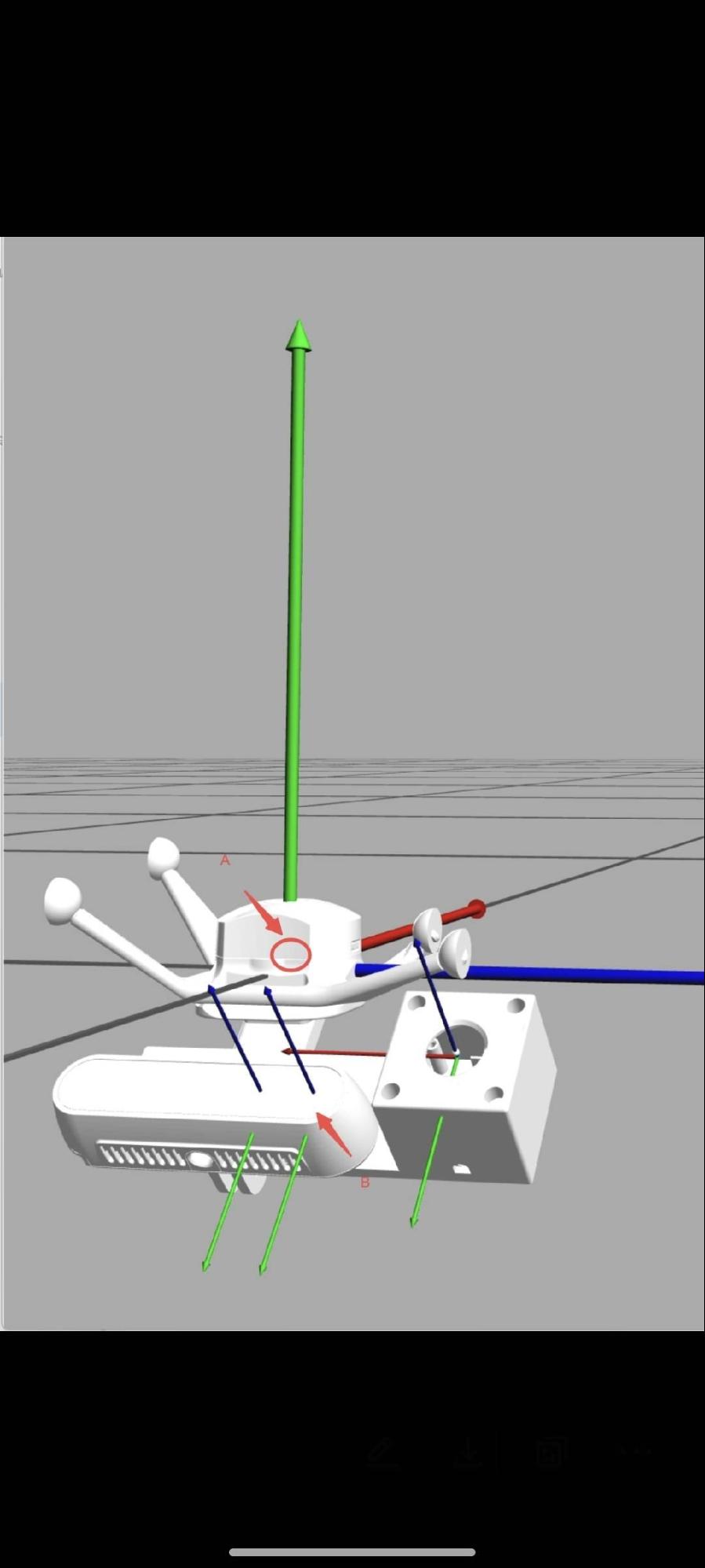 |
|---|
The camera coordinate system defaults to: right-down-front.
Camera intrinsic and extrinsic parameters are defined in the camera_params/ directory. The trackers corresponding to the three-camera system are listed in the table below:
| Camera Position | Tracker name |
|---|---|
| Header | Head |
| Fixed Camera 1 | fixed1_cam |
| Fixed Camera 2 | fixed2_cam |
Retrieve the 6DoF data for the corresponding tracker name from trackers_sixdof.h5, then apply the corresponding camera's intrinsic and extrinsic parameters to complete the camera's reprojection.
Sample Data
| Description | Data |
|---|---|
| Move the Coke on the table | HiPHI-OM-move-cola.zip |
3. Technical Specification: In-The-Wild (ITW) Dataset
-
Ecological Validity and Scene Generalization: ITW comprises a high-entropy corpus captured across diverse unconstrained environments, including residential, hospitality, retail, and logistics sectors. By incorporating stochastic variables such as non-uniform lighting, dynamic occlusions, and unstructured spatial layouts, the dataset exposes models to the long-tail edge cases of real-world deployment, significantly enhancing policy robustness against environmental distribution shifts.
-
Capture of Unconstrained Behavioral Dynamics: Unlike scripted laboratory protocols, ITW prioritizes the recording of naturalistic human-object interactions and operational logic. This focuses the training signal on the inherent "common sense" of human motion—reflecting how humans prioritize tasks and navigate social spaces—which allows for the development of humanoid agents that exhibit more intuitive and predictable behaviors in shared environments.
-
High-Throughput Distributed Acquisition: The dataset utilizes a decentralized collection strategy involving portable, low-profile sensing arrays. This methodology allows for massive parallelization of data acquisition, achieving a throughput several times higher than traditional teleoperation or laboratory-bound methods. This scalability is critical for the generation of the high-volume datasets required for foundation model training in the embodied AI space.
-
Cross-Ontology Annotation and Compliance Pipeline: The ITW framework includes an end-to-end pipeline for data desensitization (anonymization), compliance auditing, and post-processing. A specialized toolchain enables the semantic annotation of unstructured data, ensuring it remains compatible across diverse ontologies. This allows real-world behavioral "noise" to be translated into structured training signals that are usable across various robotic morphologies and task-planning architectures.
File Structure
| File Name | Description |
|---|---|
| camera_params/ | Intrinsic parameters for the head camera |
| config.json | Metadata and description of the data in this collection |
| depth_head.mkv | Head depth video |
| depth_head.csv | Timestamps for the head depth images |
| hands_keypoint_3d.json | 3D hand keypoint data |
| head_hands_sixdof.csv | 6DOF data for the head and both wrists. The first frame of the head-mounted camera corresponds to the origin of the world coordinate system, and the wrist position is represented as relative information with respect to the head-mounted camera. |
| task_info.json | Task information for this collection |
| rgb_head.csv | Per-frame timestamps for the head RGB video |
| rgb_head.mp4 | Head RGB video |
| mic.wav | Audio recording |
Depth Data
Extract each depth PNG image from depth_head.mkv according to the information in depth_head.csv.
Each PNG contains one frame of 16-bit depth data.
Parse code: read_png_16bit.py
Output result example:
Hands Keypoint 3d Visualization
Data Structure of `hands_keypoint_3d.json`
Each video directory contains a `hands_keypoint_3d.json` file storing per-frame 3D hand keypoints and MANO parameters. Top-level schema:
-
quality_exclusion: Indicates whether the entire video should be excluded (e.g., due to excessive missing data).
-
quality_summary: Aggregated statistics such as total frames and confidence distribution.
Frame-level schema (frames["<timestamp>"]):
Joint Order (21):
wrist, thumb_cmc, thumb_mcp, thumb_ip, thumb_tip, index_mcp, index_pip, index_dip, index_tip, middle_mcp, middle_pip, middle_dip, middle_tip, ring_mcp, ring_pip, ring_dip, ring_tip, pinky_mcp, pinky_pip, pinky_dip, pinky_tip
Usage Notes:
-
Coordinate System. All 3D coordinates are in the OpenCV camera frame: +X right, +Y down, +Z forward; unit is meters.
-
Confidence Filtering. Only frames with confidence == "high" should be used for training/evaluation. Low-confidence hands are kept for completeness but are excluded from temporal smoothing.
-
Tail Frames. Frames marked with excluded == true and exclude_reason == "tail" correspond to the last 2 seconds of the video and should be discarded due to unstable end-of-recording quality. Equivalently, drop any frame whose timestamp is greater than max_timestamp - 2.0 seconds.
-
MANO Parameters. hand_pose is stored as 15×3×3 rotation matrices (not axis-angle). Temporal smoothing is applied in axis-angle (Lie algebra) space and the result is converted back to matrices, which preserves the SO(3) orthogonality constraint. betas is smoothed by a simple Gaussian filter.
-
Left-Hand Handling. Only the MANO right-hand model (MANO_RIGHT.pkl) is shipped, so left hands are reconstructed by running the right-hand model and mirroring along the X-axis (**verts[:, 0] = -1, joints[:, 0] = -1). This must be done after MANO forward but before comparing the result with keypoints_3d_cam_m. See the inline comment in the example below.
Visualization Example
Please note: if the original RGB frame is already undistorted, do not apply undistortion again.
Parse code: example_kp_vis.py

6Dof data of head and wrist
The 6DoF of the head and wrist is calculated through SLAM algorithm and recorded in: head_hands_sixdof.csv
Wrist 6Dof data only exists when the data collector wears a wrist QR code bracelet.
Citation
If you use the data from this website, please cite this work as
Or use the BibTeX citation: